以下关于主键和唯一索引的区别有哪些是正确的(多选)()
A. 主键:默认是聚簇索引 唯一索引:默认是非聚簇索引
B. 主键不能为空,唯一索引可以为空。
C. 主键顺序为数据的物理索引。
D. 主键每个表只能为一个,唯一索引可以多个。
参考解答
B D
分析
A 注意主键是否是聚簇索引跟数据库实现有关,oracle不是,sqlserver是,因此A错误
B 正确
C 主键上建立聚簇索引才会让主键的顺序为实际的物理存储顺序,普通索引并不意味着主键顺序即物理存储顺序
D 正确
首先区分几个概念:主键约束、唯一约束、唯一索引、聚簇索引
主键约束
oracle 中创建主键约束的语法是使用primary key:
create table 表名 (
id number(8) primary key,
...
);
主键约束会确保插入的值必须唯一且非空,添加主键时会同时给此列创建唯一索引,一个表只能有一个主键约束。
唯一约束
oracle 中创建唯一约束的语法是使用unique:
create table 表名 (
col1 number(8) unique,
col2 varchar2(24) unique,
...
);
唯一约束可以保证插入的值唯一(允许为null),添加唯一约束时同时会给此列创建唯一索引,一个表可以有多个唯一约束。
唯一索引
唯一索引除了在创建唯一约束和主键约束时自动被创建,也可以使用单独的语法来创建:
create unique index 索引名 on 表(列名);
聚簇索引
oracle中聚簇索引是指,单独划分一块簇空间(cluster),将不同表的相关数据存储于簇内相同的数据块上并根据某列建立索引,以提升数据的访问效率。聚簇的特点是聚簇中索引的顺序即为物理记录存储的顺序。
例如:
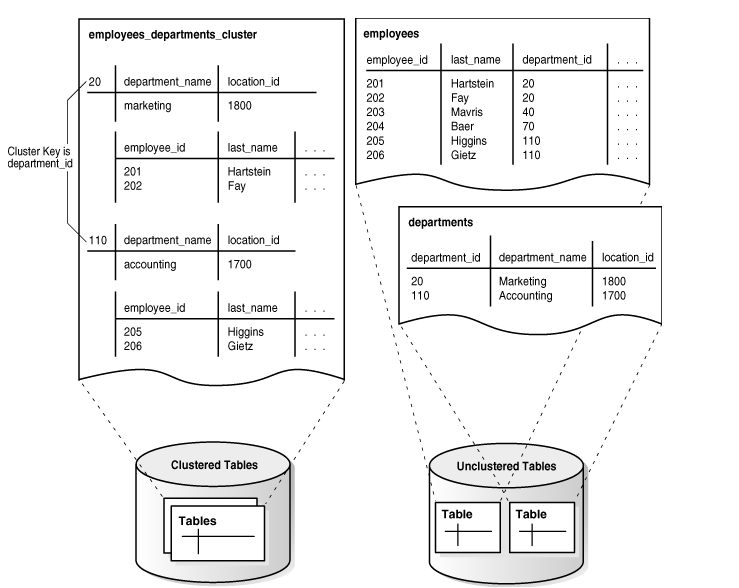
此图的右侧表示没有使用聚簇之前的数据存储结构,employees与departments两张表,它们存储在不同的数据块,如果希望同时查询20号部门的数据和该部门员工数据,必须跨越数据块进行访问,显然会造成较多的IO操作。
此图的左侧表示使用了聚簇之后的数据存储结构:在建立employees时选择按department_id值存入聚簇,同样,在建立departments表时,选择将department_id存入聚簇。
这样相同department_id 的员工记录与部门记录“聚”在一起,存储于相同的数据块中,再次执行查询20号部门的数据和该部门员工数据,IO操作非常少,效率提高。
创建和使用聚簇的步骤:
create cluster c1(id number(4)); -- 创建c1聚簇
create index c1_index on cluster c1; -- 在c1聚簇上创建索引
create table departments (
...
) cluster c1(department_id); -- 将部门表的department_id列关联到聚簇
create table employees (
...
) cluster c1(department_id); -- 将员工表的department_id列关联到聚簇